Quickwit 0.5: Distributed tracing with Open Telemetry and Jaeger, VRL, Pulsar support, and more...
Today, we are thrilled to announce the release of Quickwit 0.5.0! This new version marks a turning point in the history of the project. In addition to the usual "horizontal" new features and improvements, this release accommodates a developer-facing use case from start to finish: Quickwit 0.5 is waiting to back your distributed tracing data!
Let's unpack this!
Distributed tracing with Jaeger and OpenTelemetry
Probably the freshest face of three pillars of observability, distributed tracing is already helping a lot of developers to understand and debug their distributed systems. The most popular solution is called Jaeger. Its iconic UI displays all the RPC calls involved in a given request on a single screen.
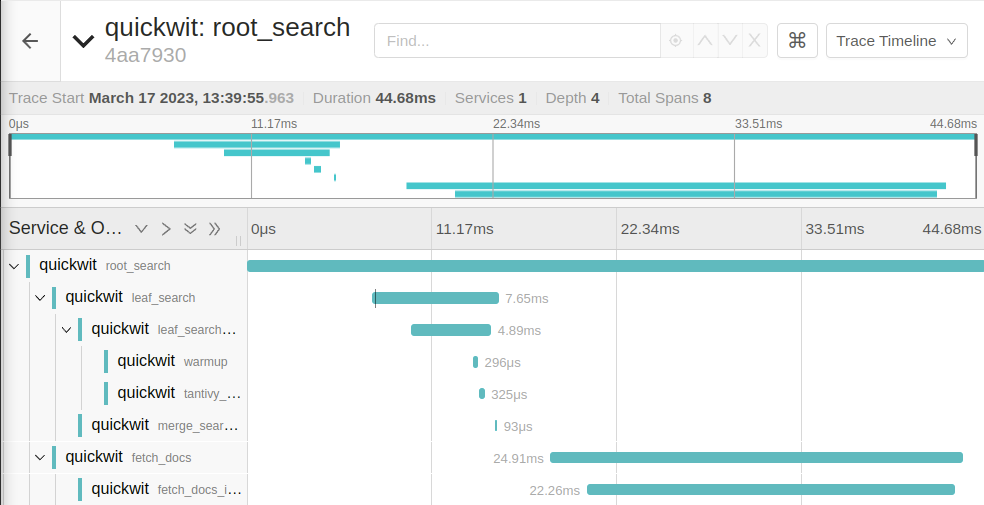
Unfortunately, while Jaeger can work standalone, it does not offer any persistence. To deal with a large amount of data or if you want your requests to stick around, you will likely need to plug Jaeger to Elasticsearch or Cassandra. These two solutions are solid and great, but they are also notoriously hard to deploy and manage.
Starting in Quickwit 0.5, you will also have the choice to use Quickwit as your Jaeger backend. You can configure Quickwit to store its data and its metadata on your object storage (for instance Amazon S3). Now that replicaton is off the table, you can comfortably spin a single quickwit node, to index and search all of your traces.
Object storage services are incredibly affordable, with price varying at around $25 per TB / month. With such a low cost, you can afford to be generous when setting the retention period for your traces. At some point in the future, you may find yourself revisiting an issue that was left hanging in your bug tracker for a long time. You will thank yourself for the longer retention!
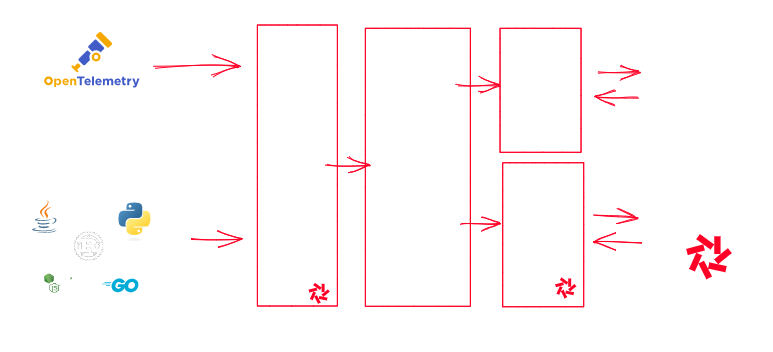
The easiest way to ship your traces to Quickwit is via OpenTelemetry. Quickwit 0.5 indeed comes with an OpenTelemetry GRPC endpoint. You can either plug the OpenTelemetry Collector to Quickwit, or you can configure your application to ship the logs directly to Quickwit.
Once this is done, all that is left is to start jaeger with the grpc plugin storage pointing to quickwit.
A tutorial is available here.
Control plane (finally!)
Quickwit finally got a control plane. When you create an index and attribute it a source, the control plane is the one in charge of finding a node in your Quickwit cluster to run the indexing of this source.
As a side effect, the Quickwit CLI does not talk directly to the metastore anymore.
Instead, it takes a new --endpoint argument and communicates with the control plane, via the Rest API.
VRL transforms
It is fairly common to deal with a dataset that is not exactly in the right format. Maybe some field needs to be parsed? Maybe some field needs to be extracted using a regular expression?
We do our best to make our document mapping a little bit smarter everyday, but sometimes you just need to pull out the big flexible gun of scripting. That's why we made it possible for you to modify your documents using VRL, a scripting language developed by the Vector (now part of Datadog).
This is done at the source config file.
For instance, if you are receiving logs in the syslog format, shipped in a Kafka source.
{ "body": " 2023-03-15T18:23:15.003Z mydomain.com myapp - My brilliant application message." }
You can now parse using into the following configuration:
version: 0.5
source_id: my-kafka-source
source_type: kafka
transform:
source: |
. |= parse_syslog!(.body)
del(.body)
And Quickwit will index the following, nicely structured document:
{
"appname": "myapp",
"hostname": "mydomain.com",
"message": "My brilliant application message.",
"timestamp": "2023-03-15T18:23:15.003Z"
}
Pulsar source
Since version 0.4, Quickwit natively supports Kafka, making it possible to ingest GB/s of documents over several indexers. Did a node just catch fire? Indexing gets automatically rebalanced thanks to Kafka's consumer group. As it was demanded, we are adding support for Apache Pulsar in Quickwit 0.5!
If you are on the fence on which messaging solution you should plug into Quickwit - we still recommend Kafka.
And plenty other good things...
This is only a fraction of our changelog. You can have a look at the exhaustive list of added features here.
What's coming next?
Quickwit 0.5 is just being released today, but Quickwit 0.6 is right around the corner. Most of its changes have already been implemented. They just did not make the cut for Quickwit 0.5 to allow for more time to polish, test and document these changes.
The main improvement will be regarding the so-called fast fields. Fast field is the name of our columnar format.
In addition to the inverted index (used to search documents), the docstore (used to return full documents), it is
sometimes handy to store fields in a columnar format to run aggregations on them for instance.
So far, a fast field had to be declared explicitly in your schema. This limitation was preventing the use of aggregation when using quickwit in a schemaless manner. In Quickwit 0.6, all of these limitations will be lifted, making Quickwit a potent solution for your schemaless & OLAP use case.