Quickwit: A highly cost-efficient search engine in Rust
Meet Quickwit 0.1! A super cost-efficient search engine is born!
I am happy to announce the release of Quickwit 0.1. It is time for a long-overdue blog post explaining what we have been cooking quietly at Quickwit.
Two search use cases with drastically different cost models
We started Quickwit with the following observation: Elasticsearch is the one-size-fits-all solution for search... But from a cost angle, there are really two big types of search engines, begging for two different solutions:
- Public search engines help anyone to find a document within a common public dataset. In this category, you will find web search engines like Google or Bing, of course. Amazon (or any e-commerce search), Twitter, Wikipedia, Github, Reddit indeed, etc., also fall into that category.
- On the other hand, private search engines allow a restricted set of users to search on a private dataset. In this category, you will find your log search engine, your Gmail search, etc.
Let's draw a scatter plot of these search engines, where X is the size of the corpus searched, and Y is the average number of QPS (query per second). We observe that the two categories appear scattered along two well-separated lines.
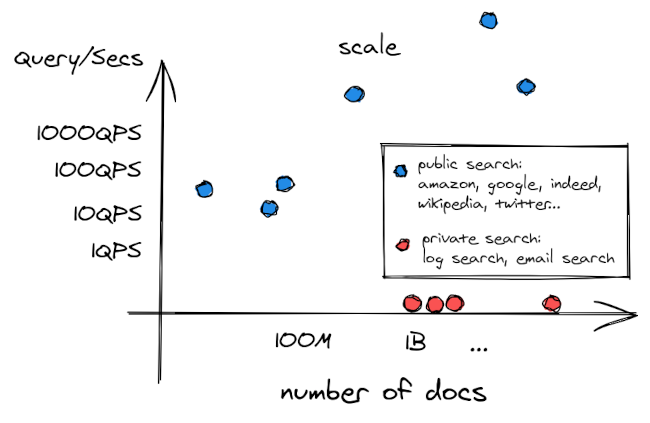
The ratio number of documents / QPS are radically different. Sure, Google is search through a gigantic number of web pages... But proportionally, its traffic is even larger! On the other hand, a medium-size successful startup may have hundreds of GB of logs to search and less than one hundred queries per day.
As you might expect, the cost models of these two types of search engines are drastically different!
For instance, if you are running a successful e-commerce website, chances are your most expensive hardware cost is the compute (CPU+RAM) time spent searching. Also, the return on investment of your search engine is probably high enough to make cost efficiency the last of your concern. No one wants to be too frugal with the goose that lays your golden eggs!
If now you are considering your typical log search engine, the equation is very different... SSDs suddenly become half of your hardware cost. The rest of your bill is your compute power, but the CPUs of your servers are spending most of their time idle. Their second favorite activity is indexing... And sometimes, something magical happens. A user comes and runs a query. All of your CPU cores wake up in unison and get busy returning your results as fast as possible... Only to resume their nap.
Elasticsearch was designed with the public search problem in mind, and addresses it brilliantly. At Quickwit, we decided to challenge the status quo of private search engines by precisely focusing on its Achilles heel, the cost-efficiency.
A cost-efficient distributed search engine
The Quickwit search engine backbone is based on tantivy's shoulder, the Lucene-like rust library that we are proud to use and maintain. However, tantivy remains a library. As performant as it is, it does not offer any mechanism to scale horizontally indexing and searching. That was the first Quickwit challenge.
Segment replication
The most obvious low-hanging fruit is indexing.
Our solution is simple: index your data once and upload it to an object storage to make it available to any instance. The object storage takes care of replication. This approach of indexing once and replicating the index segments is commonly referred to as segment replication. Elasticsearch, on the other hands, relies on document replication.
Each in-sync replica copy performs the indexing operation locally so that it has a copy. This stage of indexing is the replica stage. Elasticsearch docs
Right there, we are dividing our indexing CPU time by 3.
Separating storage and compute
The next step is more difficult. We want to reduce your CPU idle time. The only way to do this is to ensure that your "compute hardware" is not tied to a specific piece of the index. People call this property separating storage and compute...
To understand the challenge, let's break it into 3 subproblems:
- We do not want to keep any in RAM data structure about the index we are targeting. Any operation required to "open an index" needs to happen when the search request arrives.
- Our IO is done against a high latency object storage. To give you an idea, S3's time to first byte is about 70ms. This is 7 times slower than your good old spinning hard drive.
- The throughput when reading a file from S3 is not great either. Count 70MB/s.
Opening an index upon each query

Stateless search is akin to a standing start race. Receiving the query is the equivalent first crack of the starter gun. When you hear it, you better be ready.
Opening a large index usually requires loading all kinds of metadata from different file locations. On SSD, it can take a second. On S3, this would take minutes.
To solve that, we use a small hot-start bundle to turbo start in 70 ms straight from S3.
Solving S3 low throughput
S3 is known to have a bad throughput, around twenty times lower than SSD. But it is no more the case when you can fire parallel requests on S3.
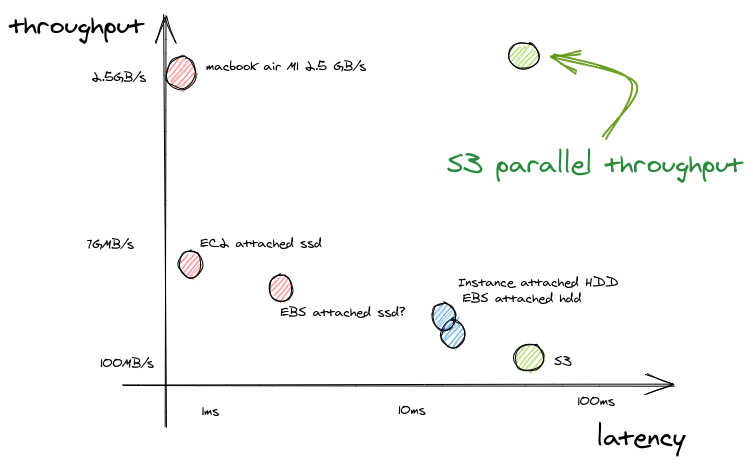
Search engines generally rely on the OS to schedule their IO and do prefetching. Quickwit schedules its own IO and concurrently downloads the data to maximize its possible throughput. In practice, we do observe a throughput of 1GB/s over the span of a query. This is the kind of bandwidth you could expect from an SSD.
Staying subsecond with a 70 ms latency
Every round-trip to S3 is yet another excruciating 60ms wasted. It is like operating a restaurant where the kitchen and the dining tables are two hundred meters apart. As a waiter, you'd probably want to minimize the back and forth trips.
Quickwit uses a custom index format to make search possible with a critical path of only 3 random seek.
With this last challenge solved, we can finally offer a truly separated compute and storage search engine. And this unlocks many benefits:
- Stateless instance, any instance can answer any query.
- Adding and removing instances takes seconds, no data moves.
- Replication is delegated to an object storage.
And this offers many other possibilities that we are just starting to unveil with our release, like simplified high availability:
- We use a gossip algorithm for cluster formation to not worry about a leader or consensus.
- The distribution of the queries is done via rendezvous hashing to create cache affinities.
- And this is only the beginning!
What's in Quickwit 0.1?
Time to speak about what we are shipping today.
This is our first release, and it lays out the foundations of a cost-efficient search engine.
Concretely, Quickwit 0.1 takes the shape of a command line interface to create, index, and serve a search cluster with the following main features:
- Fast indexing powered by tantivy
- Revamped index data structure layout to open and read an index directly on object storage
- Distributed search with stateless instances
- Cluster formation based on SWIM protocol
- Configurable mapping
- Natural query language
Check out our quickstart guide and read our docs, and for the most curious, we encourage you to look at the code as we took time to make it clean and simple.
What's next?
In the short term, we will handle bug fixes and feedbacks. Our roadmap is not marble-engraved, but we can already share with you what we have in mind for the following months:
- a production-ready metastore
- an indexing **server
- aggregations
- other object storages support
- ... and many exciting stuff that we'll keep secret for the moment 😉
We'd love to hear about your use case, as it can really help us prioritize features on our roadmap.
Happy testing!