S3 Express speculations
Amazon just announced at re:Invent 2023 a new tier for Amazon S3 called S3 Express. We had the opportunity (thank you Amazon!) to beta test this new service with our distributed search engine.
This blog post addresses two different subjects:
- what is S3 Express, and what it means for Quickwit?
- my speculations on how S3 Express works
What is S3 Express?
Here is a table that sums it up. Skimmers can digest this table and jump to the next section.
| Standard S3 | S3 Express | |
|---|---|---|
| Latency (ms) (90%) | 50ms? | 5ms? |
| GET request COST Per 1000 Request | $0.0004 | $0.0002 (assuming a payload lower than 512KB) |
| Storage cost (USD per TB.month) | $25 per TB.month | $160 per TB.month |
| Durability | 99.999 999 99s. Replicated over 3 availability zone. | Only replicated in one availability zone |
It has been already been discussed in many places. In particular, I recommend the blog post from WarpStream, which addresses the discussion about pricing very well. Let me just tell you about our perspective about this new service.
When we entered the beta program, pricing was not yet fixed. We just knew that S3 Express would be a new tier for S3 with:
- single digit millisecond long tail time to first byte (TTFB),
- cheaper small GET/PUT requests
- storage being more expensive
- single AZ replication
The latency and the cheaper GET requests got us very excited. Let me explain why...
A single digit Time-To-First Byte (TTFB)
S3 suffers from a relatively high latency and a low throughput.
Every time you emit a GET request, you can typically wait around up to 30ms to get your first byte of data, with much higher tail latencies (80ms is rather common). The throughput is then of about 80MB/s.
As a mental model. You can imagine S3 as an infinite amount of very old HDDs you access through the network. As a bonus, you get to reminisce the year 2000s and the Map Reduce paper.
Working around the throughput is relatively simple, you can run several GET requests concurrently. In that case, network throughput will be the bottleneck.
Latency is much trickier. A lot of Quickwit's innovation is about taming latency, and get the best possible performance out of object storages. Despite our best efforts, from a cold start (nothing is in cache, the process just started), we still have a critical chain of 4 consecutive reads to run a search query.
By critical chain of reads, I mean that the first read informs us of what range should be read in the second read, and so forth. In other words, a search request on Quickwit (on S3) always takes longer than 4 times S3's latency, or somewhere around 150ms.
We came to accept this irreducible latency as if it was a physical constant. This is not too terrible when you think about searching into TB of logs. For small requests however, it is a bit of a downer. S3 Express was really great news for us as it meant all of our small queries would get instantly much faster.
We ran a proper test with Quickwit. The S3 Express's SDK is not available for rust yet, but the S3 team provided us with documentation of the new API, so we managed to get a small client working. I can confirm S3 Express works as advertised: our small GET requests (get_slice calls on the left of the trace screenshot) all responded with the single digit latency. Here are the traces of two queries running on a small index with a single split.
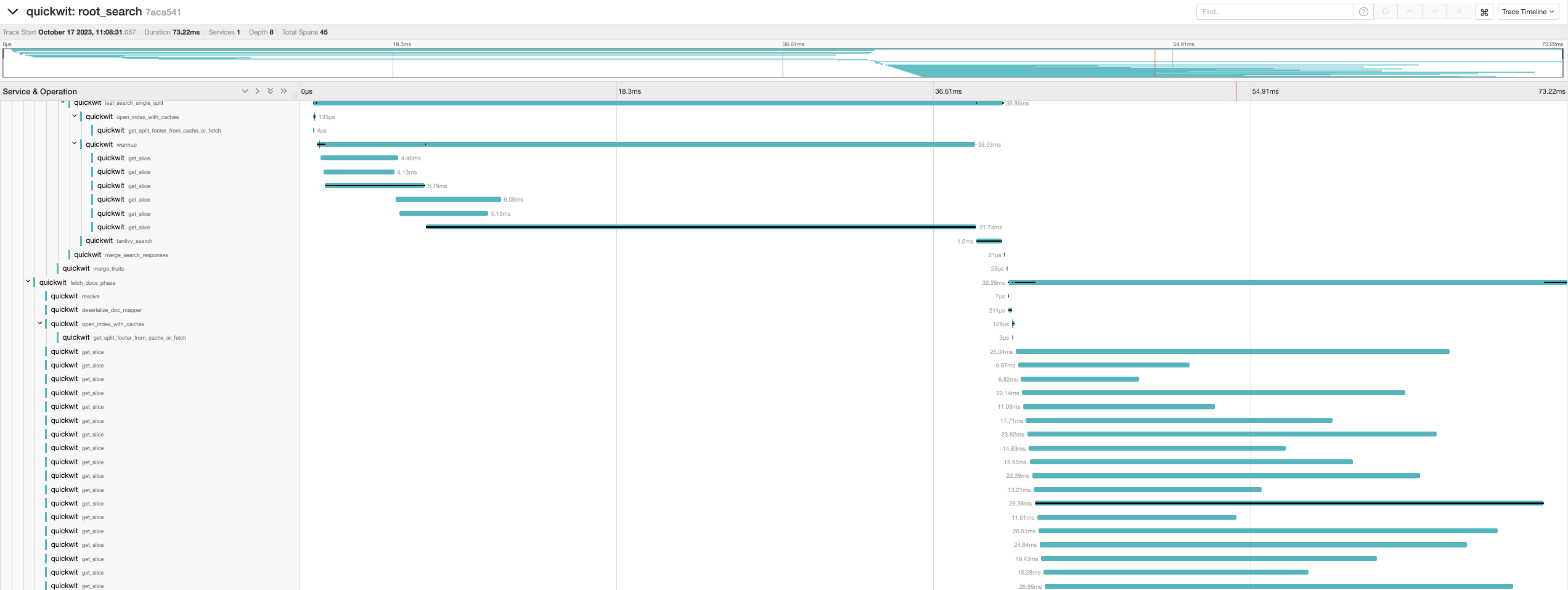
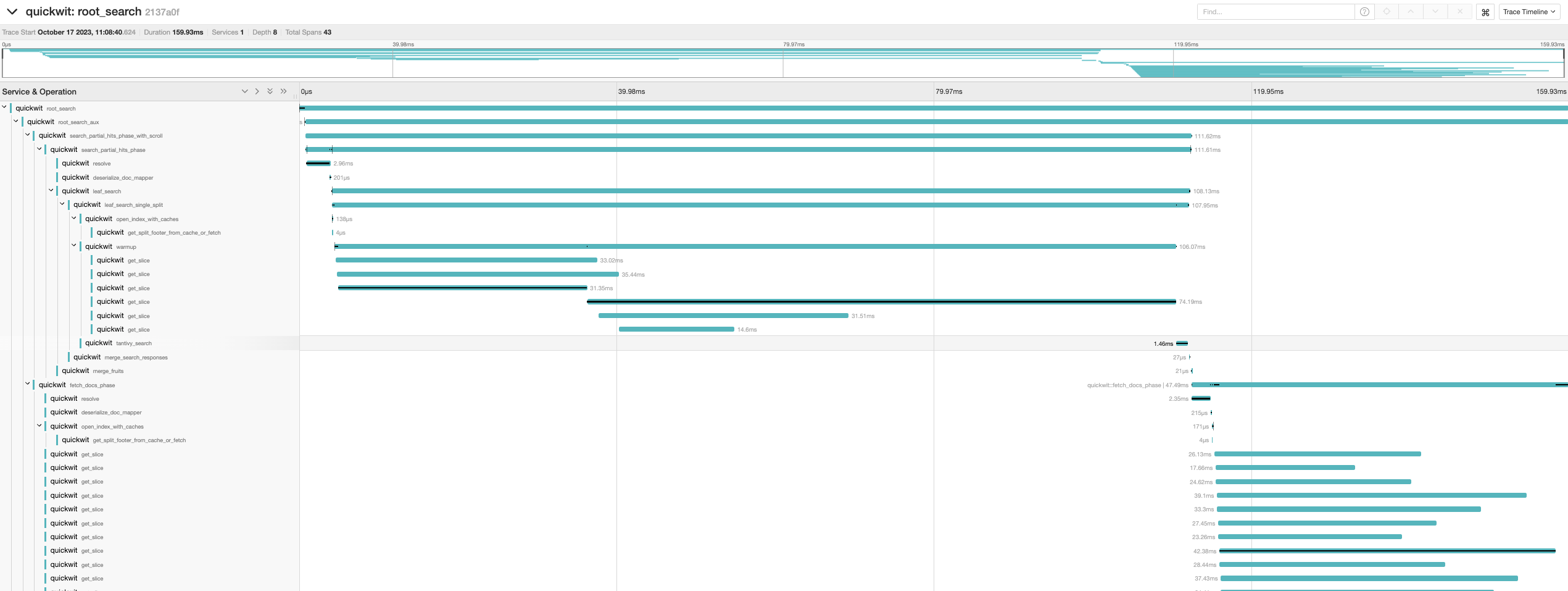
On larger queries however, using S3 Express with Quickwit does not make much of a difference.
Pricing
The three characteristics that matter to pick the most cost efficient product to search into logs are:
- retention
- volume of data
- Query per second (QPS)
You can really think of it as a 3-dimensional space, partitioned into different regions where different products (Quickwit , Elasticsearch, Clickhouse/Loki) reigns supreme.
Quickwit's kingdom is where you have a lot of data (> 1TB) and/or a high retention, and a low QPS. Without getting into details, the higher the retention, the easier it is to justify the cost of indexing. With a high number of QPS on the other hand, the cost of GET requests becomes predominant, making Quickwit less competitive at least on S3.
S3 Express could have been a game changer for us. The new pricing meant that without any extra work on our side, our "Kingdom" would suddenly get bigger. Unfortunately, to really open Quickwit to more use case, the price decrease would have to be much more (10x) significant. WarpStream came to the exact same conclusion.
How does S3 Express even work?
This is the part were I speculate.
Disclaimer: Before jumping into the discussion, let me be clear: I don't have any insider information on the subject, and the following is just speculations from a fellow engineer. This is just nerdy pub talk (I'd love to hear your thoughts about it though).
To answer the question of how S3 Express is this fast is equivalent to explaining what composes the latency of S3 in the first place.
Travel across availability zones
Let's start by the elephant in the room.
Standard S3 targets a region (e.g. us-east-1) while S3 Express targets a specific availability zone (or AZ).
Physically, a region is a set of several collocated availability zones (usually 3). Each availability zone is a different gigantic datacenter. They are placed at a reasonable distance one from another other. Two zones should be:
- distant enough to reduce the risk of a disaster hitting both zones at the same time;
- close enough to still over a few milliseconds of latency.
Concretely AZs can be as distant as 100km (60 miles). Traveling this distance in optic fiber translates into 500 microsecs. (By the way did you know latency is higher in an optical fiber compared to copper cables?). This is generally what experience shows: Cross AZ round-trip latency is below 1 millisecond.
Obviously a single round trip from your compute to a server in a different AZ (in the same region) cannot explain the drop in latency.
A GET request probably requires:
- fetching metadata about the targeted object
- checking IAM permissions (more on this later)
- fetching the actual data
- repair operation if needed (as we will see in the erasure coding section)
- log the operation for billing purpose (probably asynchronous however)
- log the operation in an audit log (probably asynchronous however)
- ...
But I don't think we can come up with a chain of 20 RPCs synchronous with the call here. The single AZ change cannot alone explain the drop in TTFB tail latency.
In fact, I suspect that starting from S3 Standard, just restricting the system to one AZ would just shave off a few milliseconds.
My opinion? The elephant in the room is probably a calf.
IAM
Every time you run a request on S3, AWS has to check that your credentials grants you the permission to perform this operation. It probably works by sending an RPC to a heavily sharded and replicated eventually consistent centralized system that has to handle one bazillion request per second.
These RPCs are probably impacting tail latencies.
In S3 Express on the other hand, the new SDK uses our credentials to create and refresh a session token. During the beta, this session token was valid for 5 minutes. This token is signed by AWS, allowing for decentralized verification: S3 can avoid the wait entirely and check on its own if an operation is authorized or not.
Erasure coding
Amazon replication strategy is unknown, but they probably do not store three full copies of your data on these three AZs. They probably rely on a technique called erasure code.
Even with heavy constraints like needing to sustain events disconnecting an entire AZ AND dealing with a reasonably small ratio of corrupted disks, depending on their strategy erasure coding can still give them a storage efficiency between 50% and 70%. It means to store 1TB of your data, they probably need a bit less than 2TB of hard disks. This is a much better than store 3 full copies of your data.
The impact of erasure coding like Reed Solomon on latency depends on the way you decide to read your data.
the optimistic/frugal way is to read your data blocks and hope everything will be fine. The problem with this approach is that if repair is needed, then extra round trips to fetch parity blocks will be required. These reads usually mean an extra round trip to servers in a different AZ.
the pessimistic/prodigal way is rarely discussed, but is quite interesting. The idea is to lean on erasure coding to actually reduce your latencies. You pessimistically fetch all of you data blocks and your parity blocks (
N+P). Instead of waiting for the slowest server to reply, you can reply as soon as you have enough blocks (N). You can read about this technique here. The downside is that this technique comes with some read amplification.
My hunch
S3 probably uses erasure code using the optimistic/frugal way both in S3 Express and S3 Standard. The single AZ setting in S3 Express probably helps here.
SSD vs HDD?
Do you think S3 stores its data on SSD or HDDs nowadays? I asked that question on twitter:
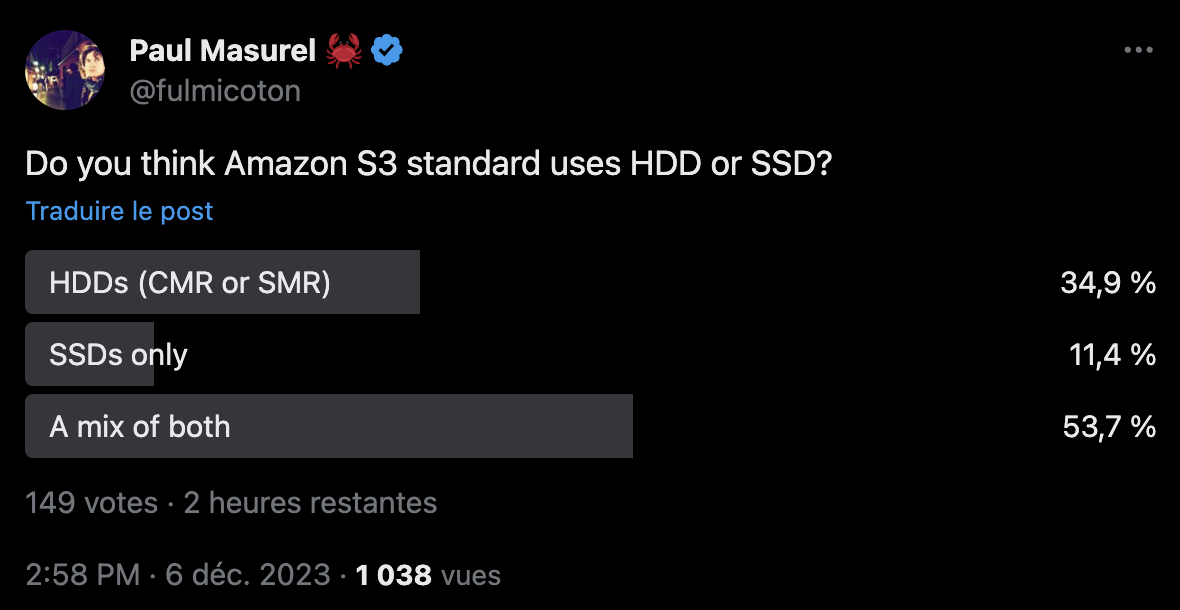
Here is a bag of facts:
S3 was available since the launch of AWS, in 2006. Amazon S3 back then cost $150/TB. Since then, both price and TTFB have massively improved.
In 2006, SSDs were not an option at all. In 2020, SSDs were still about 5 times more expensive than HDDs. Today, storing 1TB of data on an SSDs costs about 2 times the cost of storing data on HDDs. At this rate, it is projected that SSDs will become cheaper than HDDs in 2026. An HDD has a TTFB of about 10ms.
We do not have any information about whether or not Amazon S3 Standard is using SSDs or HDDs nowadays.
S3 Express on the other hand is certainly only using SSDs for storage, given the single digit latency.
My hunch
Metadata are probably stored in SSDs and RAM. For the data itself, S3 Standard probably stores your data on a range of storing device.
This is not even just a SSD vs HDD question. All HDDs are not created equal. Super large HDD offer a lower cost per TB, but come with a lower amount of available IOPS per TB.
When Amazon detects how often you data is accessed, it probably promotes/demotes it to storage device with different characteristics.
CPU operations and buffering
S3 is not just about IO. It has to run CPU intensive operations like erasure coding and encryption. Indeed, since January 2023, your S3 data is encrypted using AES-256 by default.
My hunch
In theory, these operations operate on very small blocks (256 bits for AES, and less than 512 bytes for popular erasure coding techniques) and are compatible with streaming.
Modern hardware and software techniques makes it possible to run them at an incredible throughput. In fact, I would not be surprised if Amazon was offloading these operations to dedicated ASIC or FPGA hardware.
Either way, these efficient implementations may imply some kind of buffering.
Let's assume they work over a buffer of B bytes. B is most likely somewhere between 10KB and 1MB.
In other words, when you receive your first byte, S3 has already read B bytes. With a 100MB/s throughput, buffering 100KB adds 1ms to the latency.
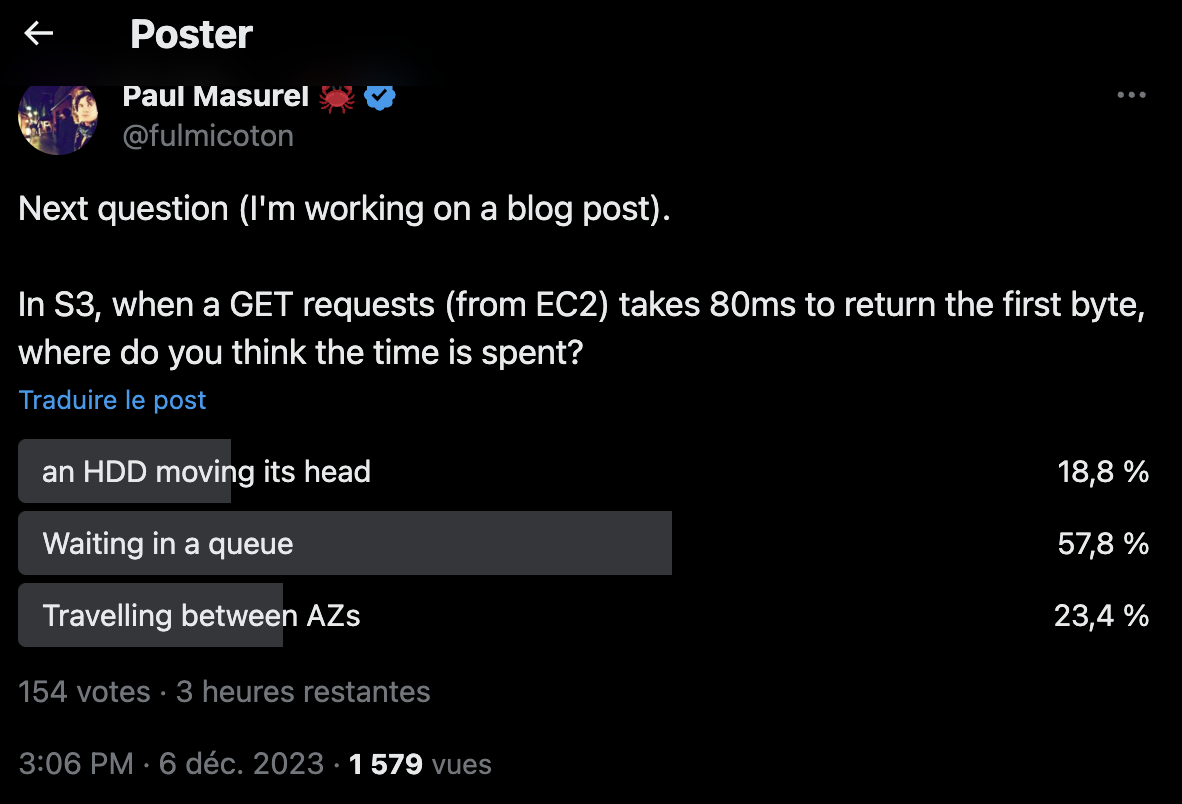
Waiting in queues
I asked on Twitter where S3 tail-latencies are spent on. Twitter polls are limited to 3 replies, so I only broke it into HDD moving its head, waiting in a queue, or traveling between AZs.
My hunch
Tail latencies are usually time spent just waiting in some sort of a queue. These queues can be explicit in your application, or more hidden, in your OS, in a different server, or even some piece of hardware.
Tweaking the load at which you operate your system for instance, is a very easy knob to turn to adjust for the latency vs throughput trade-off. Maybe Amazon operates S3 Express at a lower load than S3 itself?
Addendum: Batched IO Operations
Sergey Slotin replied to my tweet and conjectured that Amazon might be batching HDD reads to reorder them to minimize the time spent during random IOs, hence improving their IOPS. I hadn't thought about that, but this makes a lot of sense.
In conclusion
S3 Express is unfortunately not a game changer for us. Quickwit's users should probably just either stick to Amazon S3, or rely on an off-the-shelf object storage solution like MinIO or Garage.
I don't know exactly where S3 Express got its improved latency from, but my hunch is that this is the superposition of several of the points discussed in this blog post.
If my analysis is half correct, S3 Express pricing is not driven by costs, and should be highly profitable for Amazon. This new tier is deeply innovative, and Amazon will likely enjoy a monopoly on low latency object storages for the next couple of years. They can fix the price of their service without much pressure from competition.
On the other hand, this new tier is competing with their own other storage types. Most future S3 Express users are probably not using Amazon S3, Google Cloud Storage, or Azure Storage today. They are using EBS. In this situation, a more agressive price tag would have negatively impacted AWS revenues.
I hope Google Cloud and Microsoft Azure will complete their offering, so that we will eventually see a decrease in the price of this brilliant new feature.