Whichlang: A fast language detection library for Rust

While the current trend is about smart but slow large language models (LLM), we hope you will find it refreshing to read a blog post about a tiny, stupid but fast model. Less is more, isn’t it?
The need for a language-specific tokenizer
Quickwit is a search engine purposely built for logs and tracing data. “Why care about language detection?”, you may ask yourself.
While we often describe Quickwit as being designed for logs and traces, this is a bit of a communication shortcut. It would be more correct to say we are targeting “append-only” data. This includes logs of course… but also web archives, chat conversations, communication audit trails, financial transactions etc. Append-only just means that you cannot modify documents that have been inserted. Deletion is supported, but it is executed in large batches and will only happen eventually.
One of our customers wants to use Quickwit on a large corpus of short documents written in multiple languages. They wanted to use tokenizers specific to these languages.
When indexing a document, a search engine first needs to chop the document text into words. It is also usually necessary to apply some normalization like lowercasing or stemming to increase recall. We call this process tokenization, and it is language specific.
Many languages can get away with simply cutting the text according to punctuation and whitespaces. Japanese and Chinese, however, do not use whitespaces, and this operation is a non-trivial problem.
Consider the following famous Japanese tongue twister, for instance: すもももももももものうち (sumomomomomomomomonouchi). It means “Japanese Plums and Peaches are both in the Peaches” and a good tokenizer should split this into [すもも, も, もも, も, もも, の, うち]
Notice that in the original text:
- We do not have any punctuation or white spaces.
- The same character “も” is repeated many times consecutively, which suggests we cannot simply rely on some “local” dictionary matching.
Tokenization in Japanese is a non-trivial problem that requires wielding dictionaries and Viterbi’s algorithm. Fortunately, Quickwit is based on a general-purpose library called Tantivy, which already has several great tokenizers for all of these languages namely lindera, vaporetto, cang-jie, ik-rs
We were then left with the problem of identifying the language of the ingested documents, and run them through the right tokenizer.
The need for a quick language detector crate
In the Rust ecosystem, there already exists a great crate called Whatlang for performing language detection that supports lots of languages. Unfortunately, we have found it too slow (processing at about 10MB/s) for our use case. Quickwit typically indexes at >20MB/s with a single pipeline: using Whatlang would really hurt our throughput.
So far, this feature has only been requested once, so we couldn’t really afford to invest too much time in it. For this reason, we hacked together Whichlang in two days, a crate written in Rust, analogous to Whatlang, but offers better performance.
Language detection 101
Most language detection models (at least the light ones) rely on using the character n-gram frequencies. For instance, we could focus on 3-grams, and keep whitespace and punctuations (¿;。can be good clues). Given a text like “a bitter butter”, we end up with the following features: {"abi": 1, "bit": 1, "itt": 1,"tte": 2, "ter": 2, "erb": 1, "rbu": 1, "but": 1, "utt": 1}.
Note that at this point, we have dropped the position of our trigrams.
We can then create a large dictionary of frequent trigrams and derive a vector out of our set of features. Each trigram in the dictionary gets its own dedicated dimension. The coefficient for each of these n-grams can then be the count of occurrences in the document. Of course, our dictionary may not contain all of the trigrams we will encounter in our train set. We can just ignore those exotic trigrams, or map them to an “unknown trigram” feature.
Now that we have built our vector, we can run all of the classical machine learning methods. A popular solution is the Naive Bayes Model. We actually used another linear model called logistic regression.
In both cases, classifying a text boils down to computing the score of each language and picking the best. The score of a given language is simply given by the dot product of our feature vector with a constant vector specific to the language.
For our language detection needs in Whichlang, we use a multi-class logistic regression model. We use (2,3,4) n-grams for ASCII characters, codepoint / 128 and Unicode classes defined using ranges for Unicode points (useful for things like Japanese katakana).
Making it fast with feature hashing
How do we make this fast? Well, to build our feature vector, we would have to go through all the n-grams and do a lookup in our dictionary, and write into a big vector. This is really expensive. Instead of doing a proper HashMap lookup, we just use our hash itself as our vector dimension.
This technique is commonly called the hashing trick and as you may have guessed, it can potentially suffer from more collisions. However, few studies have shown that collisions have little impact on some predictive models.
We also never compute the actual feature vector and instead compute the dot product of all languages on the fly.
Barely simplified, our code looks like this:
// Fixed number of hash buckets (should be a power of 2).
const NUM_BUCKETS: usize = 4_096;
const NUM_LANGUAGES: usize = 16;
type LanguageId = usize;
fn murmurhash(trigram: [u8; 3]) -> usize {
// ...
}
fn trigrams(text: &str) -> impl Iterator<Item=[u8; 3]> + '_ {
text.as_bytes()
.array_windows::<3>()
.cloned()
}
fn infer_language(text: &str, weights_matrix: &[&[f32]]) -> LanguageId {
let mut scores: [f32; NUM_LANGUAGES] = [0f32; NUM_LANGUAGES];
for trigram in trigrams(text) {
let feature_id = murmurhash(trigram) % NUM_BUCKETS;
let language_weight = &weights_matrix[feature_id * NUM_LANGUAGES][..NUM_LANGUAGES];
for i in 0..NUM_LANGUAGES {
scores[i] += language_weight[i];
}
}
scores
.into_iter()
.enumerate()
.max_by(|(_, value_left), (_, value_right)| value_left.partial_cmp(value_right).unwrap())
.map(|(language_id, _)| language_id)
.unwrap()
}
Benchmarks and performance analysis
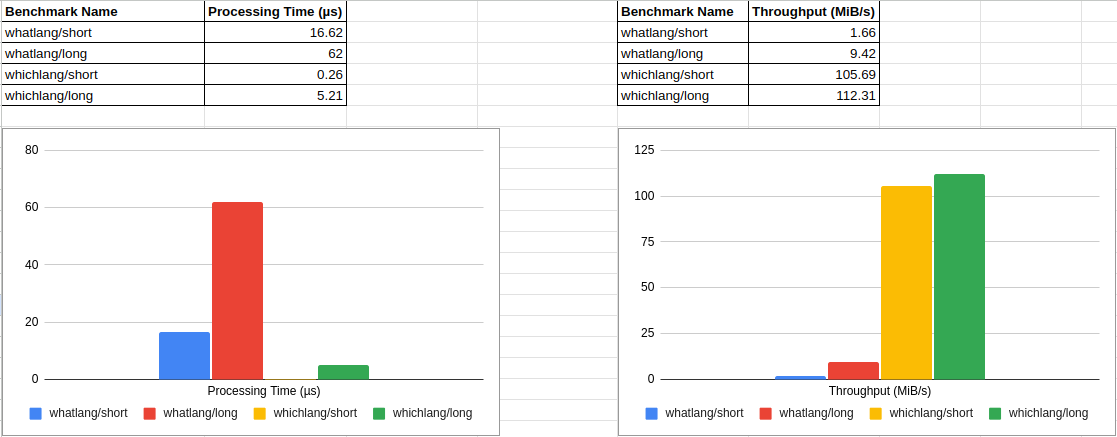
To assess the performance and accuracy of Whichlang, We initially ported its benchmark to Whatlang and proceeded with a comparison. The following charts show that Whichlang outperforms Whatlang in terms of processing time and throughput.
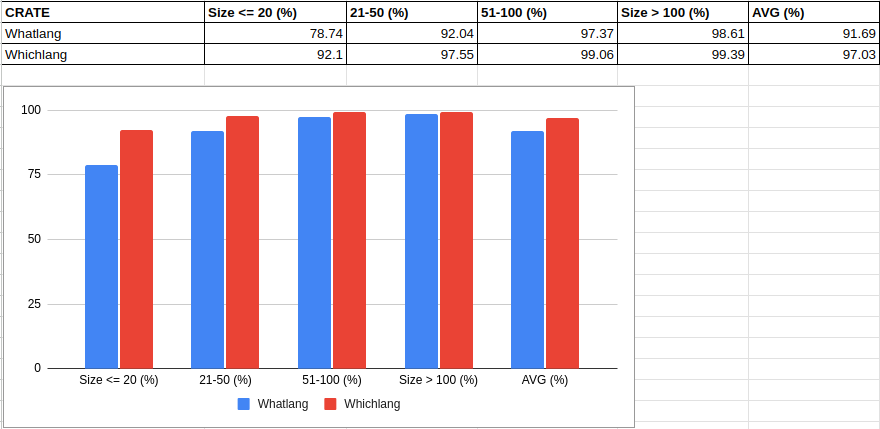
Afterward, we assessed the accuracy of Whichlang by adapting the whatlang-accuracy-benchmark. However, since Whichlang supports fewer languages compared to Whatlang; we make use of Whatlang FilterList feature to only consider languages supported by both libraries. Upon completion of the accuracy benchmark and calculating the average, we found that Whichlang outperforms Whatlang in terms of accuracy by a small margin (6%) for most groups of document size. A more detailed report including each language considered is available here.
Last but not least, here is the confusion matrix based on some European languages. In this matrix, the true languages are rows and the prediction are columns. A perfect classifier would be a diagonal matrix.
Inspecting this matrix is a great way to tell where our model does poorly and can help us guide our efforts. Here, for instance, we can spot that Portuguese is often getting mistaken for Spanish.
+--------+---------+--------+---------+-------+------------+---------+---------+
| German | English | French | Italian | Dutch | Portuguese | Russian | Spanish |
+--------+---------+--------+---------+-------+------------+---------+---------+
| 13562 | 11 | 2 | 3 | 21 | 2 | 0 | 3 |
| 14 | 36684 | 11 | 13 | 21 | 5 | 0 | 15 |
| 1 | 6 | 11551 | 8 | 2 | 4 | 0 | 7 |
| 3 | 6 | 21 | 18662 | 5 | 22 | 0 | 0 |
| 11 | 12 | 2 | 4 | 3666 | 5 | 0 | 0 |
| 4 | 3 | 8 | 23 | 1 | 9060 | 0 | 90 |
| 0 | 0 | 0 | 0 | 0 | 0 | 21220 | 0 |
| 2 | 3 | 8 | 35 | 0 | 57 | 0 | 8539 |
+--------+---------+--------+---------+-------+------------+---------+---------+
In conclusion, We were able to rapidly develop and optimize Whichlang, a fast and highly accurate language detection library based on a tiny language model. It outperforms Whatlang for the subset of languages it supports. Moreover, we are proud to say that Whichlang is an MIT Licensed open-source project that is available to everyone, allowing developers to integrate it into their applications freely.
Quickwit, our search engine targeted at logs and traces will integrate Whichlang in upcoming releases. In the meantime, you can keep on exploring all the new features we are developing for the next release using our development build. If you haven’t tried Quickwit already, Use our quickstart guide to get started.