How Binance built a 100PB log service with Quickwit

Three years ago, we open-sourced Quickwit, a distributed search engine for large-scale datasets. Our goal was ambitious: to create a new breed of full-text search engine that is ten times more cost-efficient than Elasticsearch, significantly easier to configure and manage, and capable of scaling to petabytes of data 1.
While we knew the potential of Quickwit, our tests typically did not exceed 100 TB of data and 1 GB/s of indexing throughput. We lacked the real-world datasets and computing resources to test Quickwit at a multi-petabyte scale.
That is, until six months ago, when two engineers at Binance, the world's leading cryptocurrency exchange, discovered Quickwit and began experimenting with it. Within a few months, they achieved what we had only dreamed of: they successfully migrated multiple petabyte-scale Elasticsearch clusters to Quickwit, with remarkable achievements including:
- Scaling indexing to 1.6 PB per day.
- Operating a search cluster handling 100 PB of logs.
- Saving millions of dollars annually by slashing compute costs by 80% and storage costs by 20x (for the same retention period).
| Dataset | |
|---|---|
| Uncompressed Size | 100 PB |
| Size on S3 (compressed) | 20 PB |
| Num documents | 181 trillions |
| Indexing deployment | |
|---|---|
| Indexing throughput | 1.6 PB / day |
| Num pods | 700 |
| Num vCPUs | 4000 2800* |
| RAM | 6 5.6* TB |
| Search deployment | |
|---|---|
| Searchable dataset size | 100 PB |
| Num pods | 30 |
| Num vCPUs | 1200 |
| RAM | 3 TB |
| Infra costs vs. Elasticsearch | |
|---|---|
| Compute costs | 5x reduction |
| Storage costs for same retention | 20x reduction |
In this blog post, I will share with you how Binance built a petabyte-scale log service and overcame the challenges of scaling Quickwit to multi-petabytes.
Binance's challenge
As the world's leading cryptocurrency exchange, Binance handles an enormous volume of transactions, each generating logs that are crucial for security, compliance, and operational insights. This results in processing roughly 21 million log lines per second, equivalent to 18.5 GB/s, or 1.6 PB per day.
To manage such a volume, Binance previously relied on 20 Elasticsearch clusters. Around 600 Vector pods were pulling logs from different Kafka topics and processing them before pushing them into Elasticsearch.
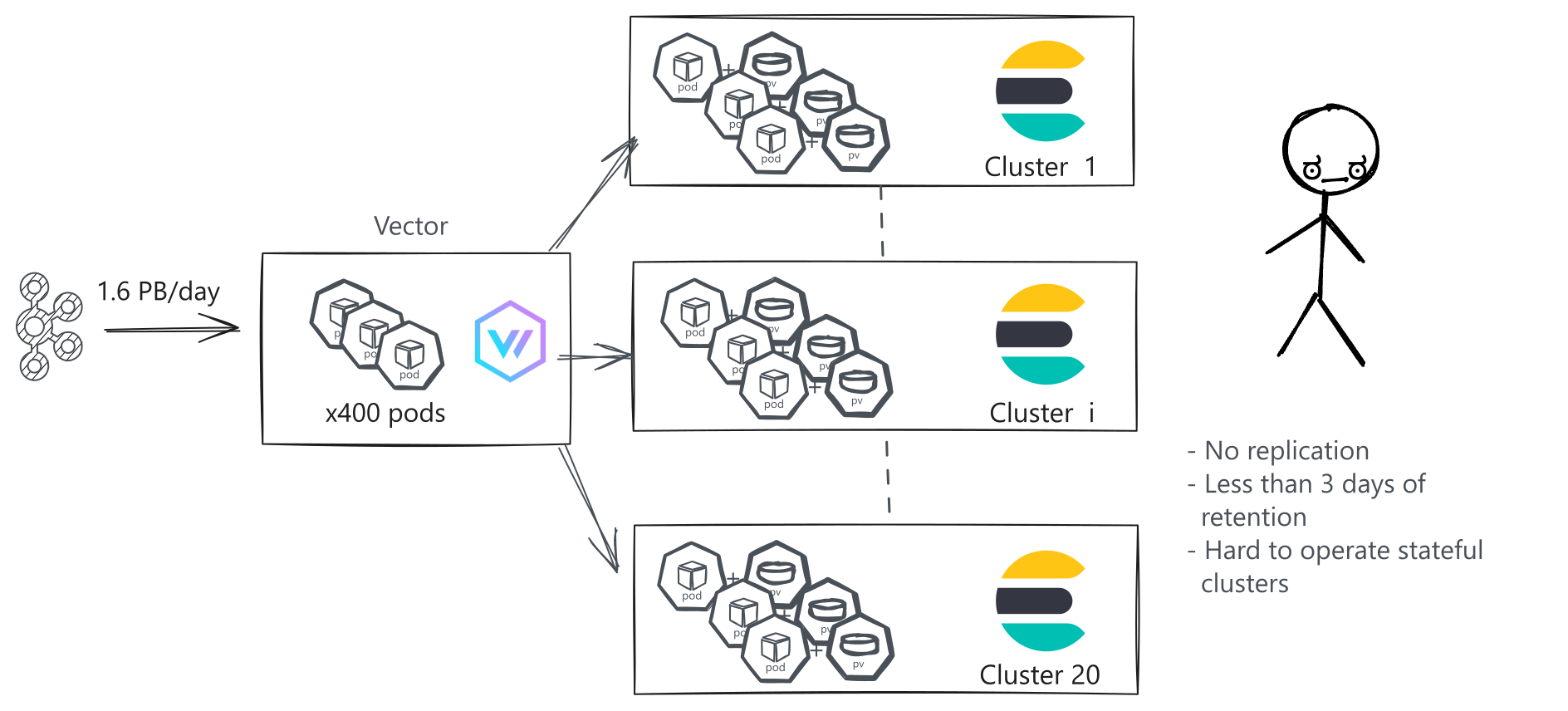
However, this setup fell short of Binance's requirements in several critical areas:
- Operational Complexity: Managing numerous Elasticsearch clusters was becoming increasingly challenging and time-consuming.
- Limited Retention: Binance was retaining most logs for only a few days. Their goal was to extend this to months, requiring the storage and management of 100 PB of logs, which was prohibitively expensive and complex with their Elasticsearch setup.
- Limited Reliability: Elasticsearch clusters with high ingestion throughput were configured without replication to limit infrastructure costs, compromising durability and availability.
The team knew they needed a radical change to meet their growing needs for log management, retention, and analysis.
Why Quickwit was (almost) the perfect fit
When Binance's engineers discovered Quickwit, they quickly realized it offered several key advantages over their existing setup:
- Native Kafka integration: It allows ingesting logs directly from Kafka with exactly-once semantics, providing huge operational benefits. Concretely speaking, you can tear down your cluster, recreate it in a minute without losing any data, ready to ingest at 1.6 PB/day or search through petabytes, and scale up and down to handle temporary spikes.
- Built-in VRL transformations (Vector Remap Language): As Quickwit supports VRL, it eliminates the need for hundreds of Vector pods to handle log transformations.
- Object storage as the primary storage: All indexed data remains on object storage, removing the need for provisioning and managing storage on the cluster side.
- Better data compression: Quickwit typically achieves 2x better compression than Elasticsearch, further reducing the storage footprint of indexes.
However, no users had scaled Quickwit to multi-petabytes, and any engineer knows that scaling a system by a factor of 10 or 100 can reveal unexpected issues. This did not stop them, and they were ready to take on the challenge!

Scaling Indexing at 1.6 PB a day
Binance rapidly scaled its indexing thanks to the Kafka datasource. One month into their Quickwit PoC, they were indexing at several GB/s.
This quick progress was largely due to how Quickwit works with Kafka: Quickwit uses Kafka's consumer groups to distribute the workload across multiple pods. Each pod indexes a subset of the Kafka partitions and updates the metastore with the latest offsets, ensuring exactly-once semantics. This setup makes Quickwit's indexers stateless: you can tear down your entire cluster and restart it, and the indexers will resume from where they left off as if nothing happened.
However, Binance's scale revealed two main issues:
- Cluster Stability Issues: A few months ago, Quickwit’s gossip protocol (called Chitchat) struggled with hundreds of pods: some indexers would leave the cluster and rejoin, making the indexing throughput unstable.
- Uneven Workload Distribution: Binance uses several Quickwit indexes for their logs, with varying indexing throughputs. Some have a high throughput of several GB/s, others just a few MB/s. Quickwit's placement algorithm does not spread its workload evenly. This is a known issue, and we will work on this later this year.
To work around these limitations, Binance deployed separate indexing clusters for each high-throughput topic, keeping one cluster for smaller topics. Isolating each high-throughput cluster did not impose an operational burden thanks to stateless indexers. Additionally, all Vector pods were removed as Binance used Vector transformation directly in Quickwit.
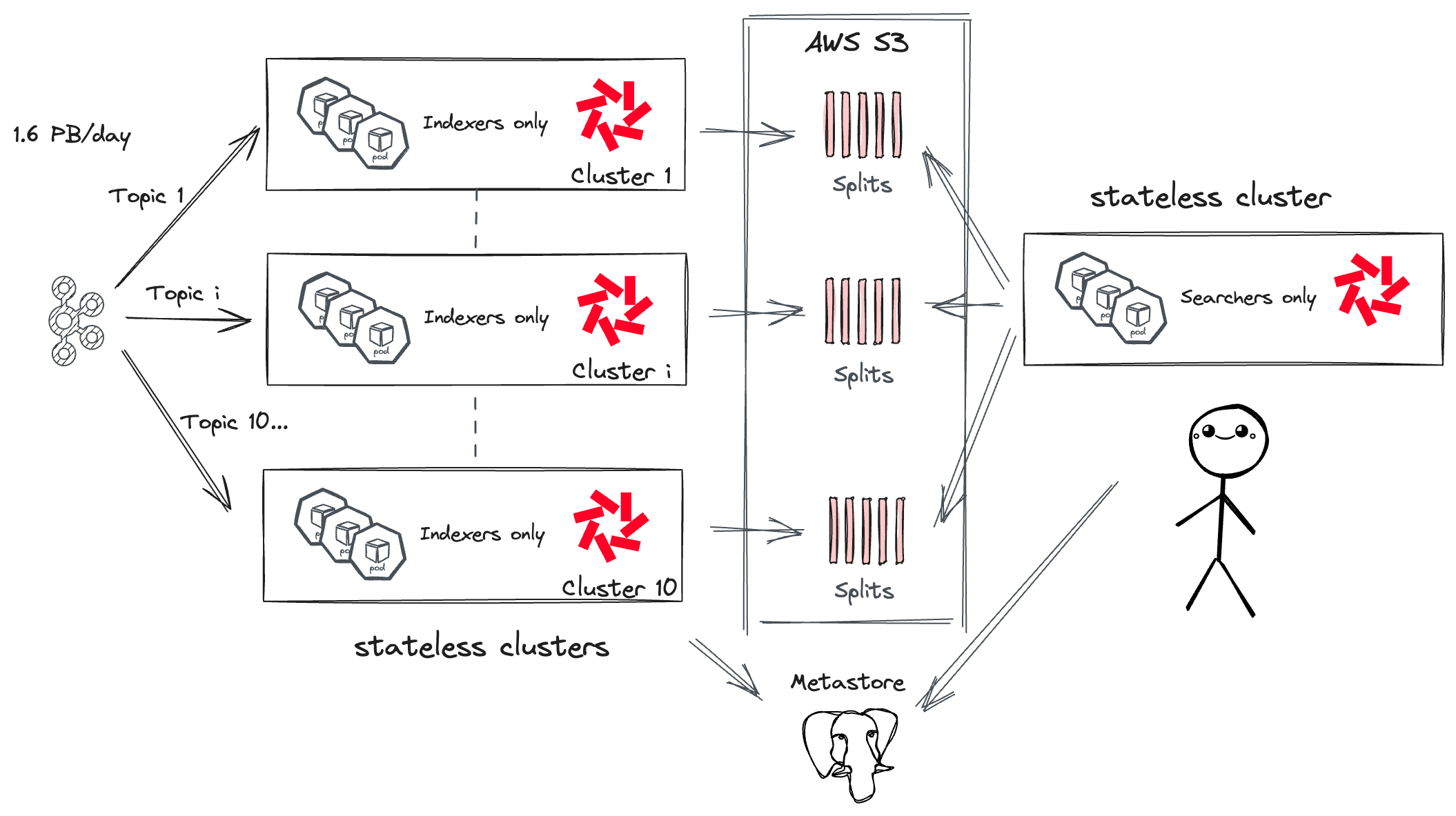
After several months of migration and optimization, Binance finally achieved an indexing throughput of 1.6 PB with 10 Quickwit indexing clusters, 700 pods requesting around 2800 vCPU and 6 TB of memory, that's 6.6 MB/s per vCPU on average. On a given high-throughput Kafka topic, this figure goes up to 11 MB/s per vCPU.
Next challenge to come: scaling search!
A single search cluster for 100 PB of logs
With Quickwit now capable of efficiently indexing 1.6 PB daily, the challenge shifted to searching through petabytes of logs. With 10 clusters, Binance would normally need to deploy searcher pods for each cluster, undermining one of Quickwit’s strengths: pooling searcher resources to hit the object storage shared by all indexes.
To avoid this pitfall, Binance's engineers devised a clever workaround: they created a unified metastore by replicating all metadata from each indexing cluster metastore into one PostgreSQL database. This unified metastore enables the deployment of one unique centralized search cluster capable of searching through all indexes!
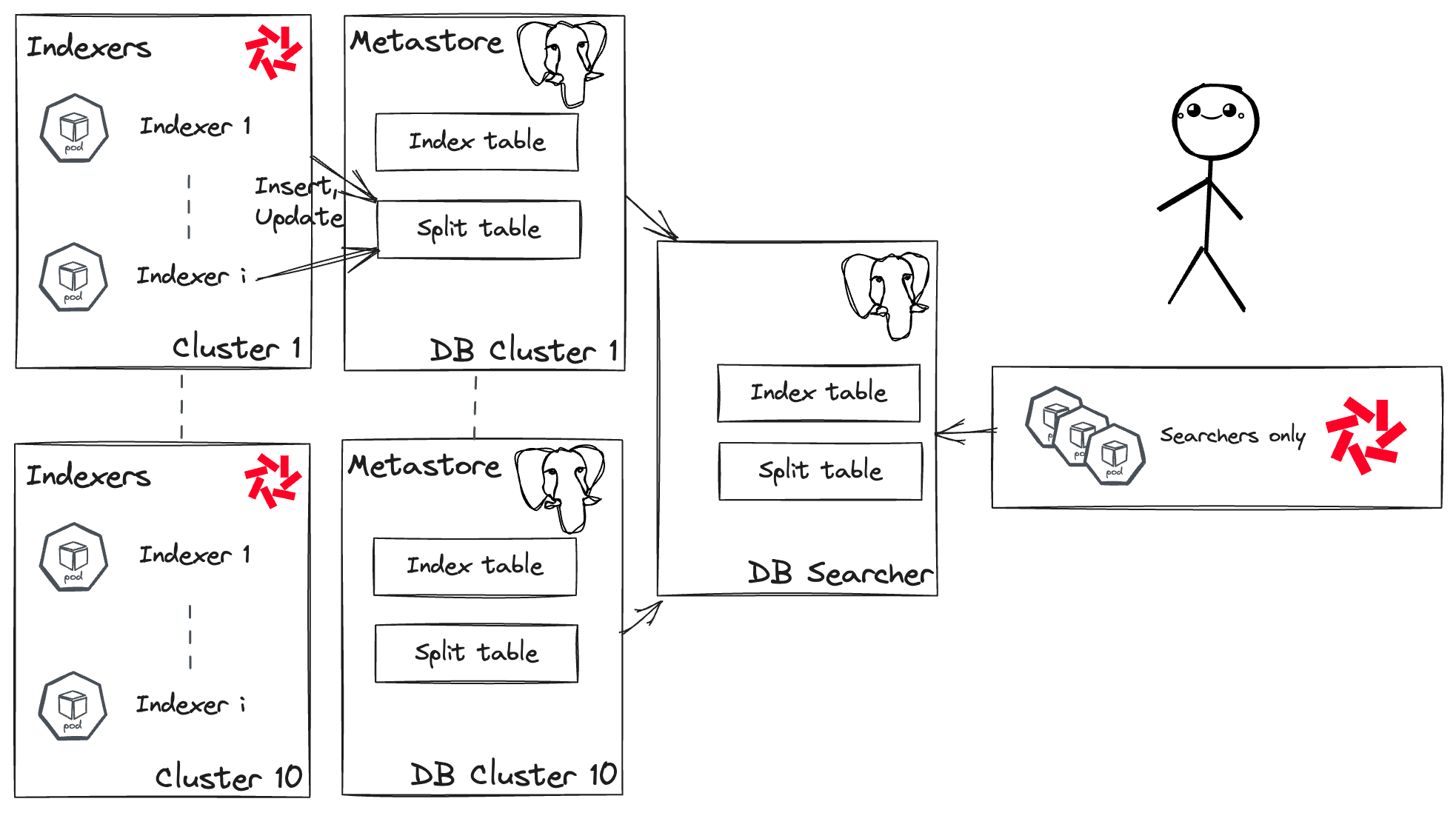
As we speak, Binance now manages a reasonably sized cluster of 30 searcher pods, each requesting 40 vCPU and 100GB memory. To give you an idea, you only need 5 searchers (8 vCPU, 6GB memory requests) to find the needle in the haystack in 400 TB of logs. Binance runs those types of queries on petabytes but also aggregation queries, hence the higher resource requests.
Wrapping up
Overall, Binance's migration to Quickwit was a huge success and brought several substantial benefits:
- 80% reduction in computing resources compared to Elasticsearch.
- Storage costs reduced by a factor of 20 for the same retention period.
- Economically viable solution for large-scale log management, both in terms of infrastructure costs and maintenance operations.
- Minimal configuration tweaking, working efficiently once the right number of pods and resources were determined.
- Increased log retention to one or several months, depending on the log type, improving internal troubleshooting capabilities.
In conclusion, Binance’s migration from Elasticsearch to Quickwit has been an exciting 6-month experience between Binance and Quickwit engineers, and we are very proud of this collaboration. We have already planned improvements in data compression, multi-cluster support, and better workload spread with Kafka datasources.
Huge kudos to Binance's engineers for their work and insights throughout this migration <3