Scaling search to 0 with AWS Lambda
In this blog post, we introduce you to the new Serverless deployment mode for Quickwit based on AWS Lambda.
The biggest value proposition of the cloud is to provide infrastructure resources that quickly adapt to the requirements of the deployed applications. Serverless takes this a step further by completely abstracting infrastructure concerns and aligning costs more directly with application usage. For example, billing for a serverless database is based on its storage size and access frequency rather than the underlying hardware.
However, one needs to be very careful with the term “serverless”. It is common for cloud services to exclusively provide a very shallow layer above their compute resources, resulting in pricing models that still incorporate substantial fixed costs due to underutilized compute resources. This is particularly true in the search engine space. Do we really want a serverless search that costs $700 per month, even if it doesn’t receive any data or requests?
Ideally, you would prefer a serverless service to Scale to zero with costs going down to zero when you don’t use the service. There should be no fixed costs associated to the service!
Having such a serverless search is hard and poses significant technical hurdles:
- Using a compute resource that is fast to provision.
- Minimizing the initialization time of the service.
- Balancing storage latency, cost, and availability.
Today, we're proud to announce that Quickwit on Lambda, built with Rust and optimized for Amazon S3 access, solves those challenges. It provides a genuinely serverless search solution for observability, or more generally, for append-only datasets.
A word about performance and costs
We were actually pleasantly surprised by the results of our preliminary benchmark. On a 20 million log dataset0, we observed:
- An indexing throughput of 27 MB/s with 8GB Lambdas.
- Sub-second response for basic queries.
- Analytics queries within 1-4 seconds.
On the cost side, we estimate that for 1TB worth of data:
- Ingestion will cost $5 compared to $500 for CloudWatch1 for a log ingestion from S3.
- Storage on S3 will cost less than $15 per month (assuming a compression ratio of 2 which is conservative for logs).
- Querying costs will depend on the searcher Lambda durations. Expect around $0.1 per 1,000 requests on 1GB, 50x cheaper than CloudWatch2. Quickwit is also capable of caching partial query results between Lambda invocations, which greatly reduces the cost of repeated queries from monitoring dashboards.
We will publish detailed results in a dedicated blog post soon. Stay tuned.
Of course, you can achieve better performance and lower the costs for larger datasets by running a dedicated cluster. Lambda deployments shine for small to medium sized usecases, especially when the ingestion and query patterns are very irregular.
Quickwit Serverless overview
Our approach to serverless search involves:
- Provisioning: We use AWS Lambda, the compute resource that has by far the best scaling capability.
- Initialization: We had already designed Quickwit's searcher to be stateless. Our goal was then to make Quickwit more scalable and easier to manage. In particular, This property happened to be aligned with the requirement of searching on Lambdas. Also, Quickwit is implemented in Rust, which is a perfect language for fast startup.
- Storage: We use AWS S3 which is the most cost-efficient, highly available storage option. Its latency is compensated by its scalability and ability to parallelize requests. Quickwit is specifically optimized for that!
A typical use case for serverless search
Let's explore a typical end-to-end use case.

Send data to a staging Amazon S3 bucket as a blob of gzipped newline-delimited JSON. This is how most services provide access to their data (e.g. AWS Cloudwatch or Papertrail exports). You can also use Amazon Firehose to perform the same kind of batching.
An Indexer picks up the file and performs the indexing operation. The resulting indexes are stored in an Index S3 bucket.
Finally, when users make queries, a Searcher is invoked. The system can scale to many queries in parallel, more Searcher functions will be spawned by Lambda to accommodate the extra load.
Let’s take a look at how this new serverless deployment is different from some leading existing solutions.
How does it compare to Cloudwatch Insights?
Cloudwatch Logs is the common way of gathering logs when running AWS resources. It has a powerful query engine on top of it called Cloudwatch Insights that makes it possible to scan through logs to perform searches and simple aggregations.
In terms of pricing structure, both Quickwit Serverless and Cloudwatch are similar: you pay for the processing necessary to ingest the data, the amount of data stored, and the number of queries you make.
The big difference between the data stored by Quickwit and Cloudwatch is the fact that Quickwit creates indexes along the data it stores. Indexes are advanced data structures that make it possible to answer queries by taking shortcuts in the dataset. This means that you usually don’t need to load the entire dataset to find what you are looking for, just a subset of it. This makes queries faster and hence cheaper.
Of course, there is no such thing as a free lunch. The drawback of this efficient querying is that you need to pay an extra cost when you ingest the data to create these indexes and another one to store them. Quickwit is the maintainer of tantivy, a highly optimized search library written in Rust. We thrive on optimizing every millisecond out of the indexing process and every byte out of the stored format to keep the overhead of the indexes small.
How does it compare to OpenSearch Serverless?
Amazon OpenSearch Serverless is a managed service that takes care of scaling your OpenSearch infrastructure automatically, both on the indexing and search side. The big difference with Quickwit Serverless is its lack of capability of scaling to 0.
OpenSearch serverless has a fixed cost of approximately $1 per hour or $700 per month (refer to the AWS console screenshot below for details). Having a service with no fixed cost is particularly beneficial when you need to provide multiple environments or separate your tenant’s infrastructure. Each additional environment or tenant would add to the cost, potentially making OpenSearch Serverless an impractical option for various scenarios.
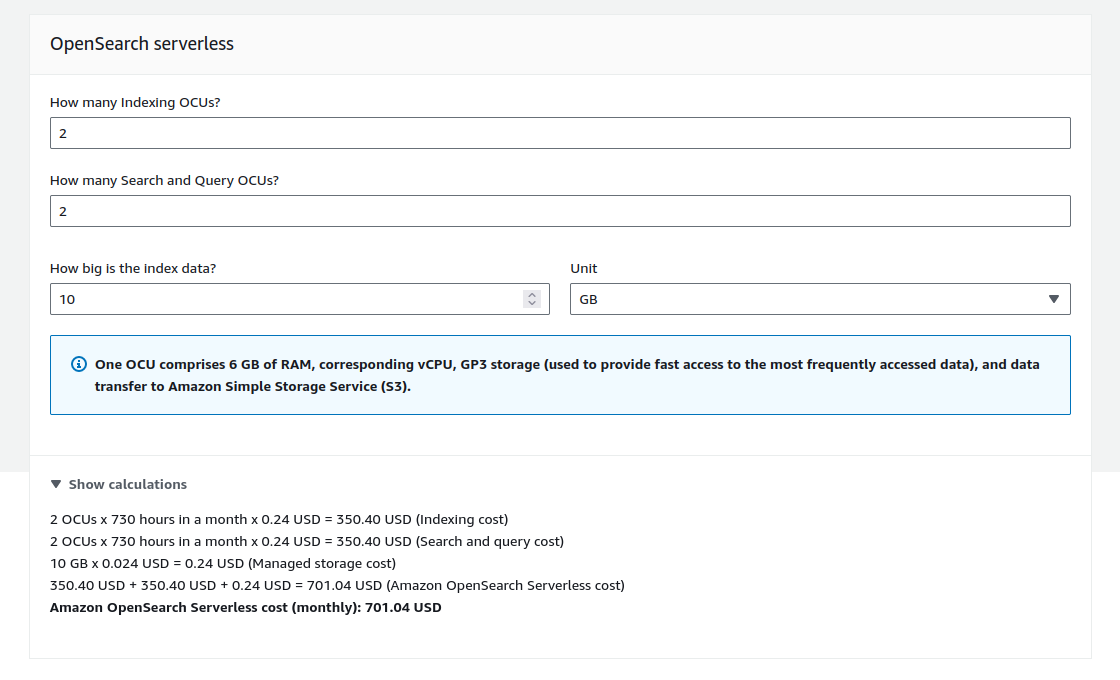 Screenshot taken on AWS OpenSearch Service pricing calculator page. The $700 price floor comes from the fact that you can't have less than 2 OCUs for indexing and 2 for search.
Screenshot taken on AWS OpenSearch Service pricing calculator page. The $700 price floor comes from the fact that you can't have less than 2 OCUs for indexing and 2 for search.
Try it out
If you are interested in running Quickwit on AWS Lambda, we have baked together a tutorial for you to get started. We can’t wait to get your feedback, come and join us on Discord!
- HDFS logs dataset. Notably used in one of our tutorials.↩
- CloudWatch ingest costs 0.05 per GB (before compression).↩
- CloudWatch Logs Insights queries costs 0.005 per GB scanned.↩