Decentralized cluster membership in Rust
Even after 10 years of programming, I still have a relentless curiosity about new software algorithms, reading papers and blog posts, and learning from other engineers. The best part, however, really comes when you have the opportunity to implement one algorithm and even customize it for your specific use case. In this post, I will walk you through my journey from understanding cluster membership fundamentals to the implementation of Chitchat, our Rust implementation of the Scuttlebutt algorithm with a phi accrual failure detector.
I will first introduce the cluster membership subject and give some details about the current membership algorithm used in Quickwit (SWIM). Why we decided to move away from it, despite being slightly faster conceptually than the successor. Then, I will explore in-depth how scuttlebutt and the failure detector algorithms work, how we have implemented them. Finally, I will describe a couple of real-world issues that we have encountered and how we solved them.
What is cluster membership?
Given a cluster of nodes, cluster membership is the sub-system that allows each node to know the list of its peers. It detects node failure and eventually, make all other nodes aware that a failed node is no longer a member of the cluster.
One common way to address this problem is to have a monitoring node in charge of checking the health of all the other nodes by running a heart-beating scheme. This approach works well for a few nodes but shows hot spots as the cluster gets larger. Another way is to put all the nodes in charge of monitoring. While this avoids hot spots, all existing heart-beating scheme offer different levels of scalability and accuracy. Some generate a lot of network traffic while others might take a bit of time to converge. All these issues combined make cluster membership a tricky engineering problem.
What is SWIM and why are we moving away from SWIM?
Since our first release, Quickwit has had a cluster membership feature in order to provide distributed search. SWIM is the algorithm currently used for this feature. It is based on a gossip style that is referred to as dissemination aka “rumor-mongering”. Scuttlebutt is different and is based on another gossip style called “anti-entropy”. Robbert et al in their paper explained the difference between both gossip approaches as follows:
Anti-entropy protocols gossip information until it is made obsolete by newer information, and are useful for reliably sharing information among a group of participants. Rumor-mongering has participants gossip information for some amount of time chosen sufficiently high so that with high likelihood all participants receive the information.
Next is a real-world example we like to use for explaining the differences between rumor-mongering and anti-entropy:
- Rumor-mongering: consider a piece of breaking news you just read from your local newspaper and decide to inform all your contacts. Those you inform also decide to inform their contacts. This style of gossiping spreads the news very quickly. However, there will be a time when people lose interest in the news, stop spreading it, and not everyone gets the chance to be informed.
- Anti-entropy: let’s suppose everyone in town on regular basis talks to a few of his contacts (3 to 5) to keep up with any news in town. This type of information exchange is slower because of the number of selected contacts. However, since everyone does this perpetually, they are guaranteed to be informed about the latest news no matter what time it takes.
The key difference here is that with SWIM, a node may miss some propagated messages within the cluster, which can lead to false-positive failure detection. Hashicorp for instance had to extend their production-grade SWIM implementation Serf with Lifeguard. Lifeguard is a set of three extensions destined to reduce false positive failure detection.
We also struggled to find a suitable library-oriented implementation of SWIM in Rust. Though we found Artillery very useful to start with and want to thank all the contributors, we wanted a more battle-tested implementation like Serf in Go.
Moreover, we found that scuttlebutt as an algorithm:
- Is easier to understand and implement correctly.
- Allows nodes to share/advertise information about themselves (service ports, available ram/disk) without any special logic.
- Is battle-tested in production-grade systems such as Apache Cassandra
How scuttlebutt works?
Scuttlebutt is a gossip algorithm with a reconciliation technique fully described in this paper. In scuttlebutt, every node keeps a local copy of the cluster state which is a map of node ID to node state. Think of it as a key-value store namespaced by node ID in which a node is only allowed to modify (create/update/delete) its own namespace. A node can apply the changes it perceives from other nodes while gossiping. However, it cannot directly update the other node’s states. Because scuttlebutt employs the anti-entropy gossip technique, all the nodes in the cluster eventually get the latest cluster state at some point. Also, notice how the concept is based on key-value store, making it easy for nodes to share information.
The following is a JSON representation of node node-1/1647537681 view of the cluster state. The number following node-1 is a timestamp and you will soon understand why we added that number. Notice how each node advertises its own grpc_address and heartbeat counter.
{
"seed_nodes": [
"127.0.0.1:7281"
],
"node_states": {
"node-1/1647537681": {
"key_values": {
"grpc_address": {
"value": "0.0.0.0:7282",
"version": 2
},
"heartbeat": {
"value": "1002",
"version": 1004
}
},
"max_version": 1004
},
"node-2/1647537802": {
"key_values": {
"grpc_address": {
"value": "0.0.0.0:8282",
"version": 2
},
"heartbeat": {
"value": "991",
"version": 993
}
},
"max_version": 993
},
"node-3/1647538101": {
"key_values": {
"grpc_address": {
"value": "0.0.0.0:9282",
"version": 2
},
"heartbeat": {
"value": "92",
"version": 94
}
},
"max_version": 94
}
}
}
The gossip protocol works as follows:
- Every second, a node randomly selects a few (3 in our case) nodes to gossip with.
- To make this node selection a bit smarter, we randomly include:
- A seed node if not selected already
- A dead node (to determine whether it is back online)
- The gossip frequency and the number of selected nodes are configurable as they directly affect the propagation speed of any cluster state change.
- Seed nodes are nodes that are known to be highly available within our cluster.
Let’s now describe the flow of a single gossip round between two nodes.
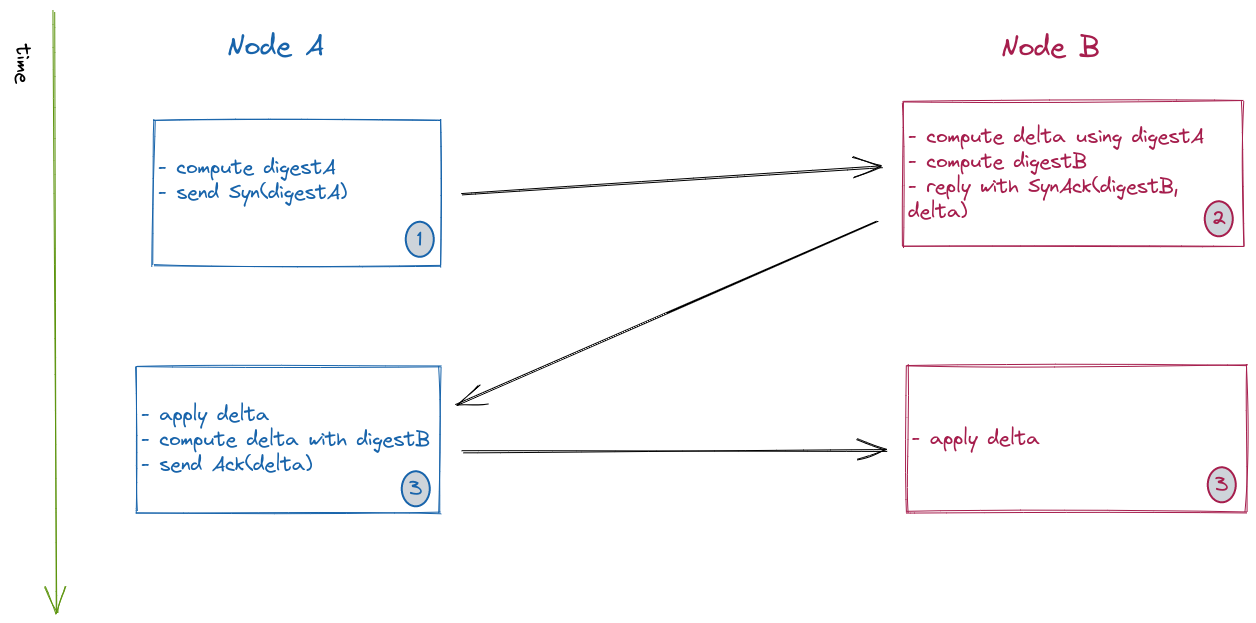
As you can see from the above figure, a gossip round is initiated by node A:
- Node A initiates a gossip round with Node B:
- Computes its digest (DigestA).
- Sends a
Synmessage with DigestA to Node B.
- Node B upon receiving the
Synmessage:- Computes a delta (AB) using DigestA: this delta (AB) contains what Node A is missing from Node B’s copy of the cluster state.
- Computes its digest (DigestB).
- Sends a
SynAckreply with delta and DigestB
- Node A upon receiving the
SyncAckreply:- Applies the delta AB (changes) to its copy of the cluster state.
- Computes delta (BA) using DigestB: delta (BA) is what Node B is missing from Node A’s copy of the cluster state.
- Sends an
Ackmessage with delta.
- Finally, Node B upon receiving the
Ackmessage:- Applies the delta BA (changes) to its copy of the cluster state.
- Digest is a map of
node_idtomax_versionthat helps compute what keyspace is missing or outdated while reducing the amount of data that needs to be exchanged between nodes. This coupled with the fact that Scuttlebutt relies on UDP rather than TCP makes it a very resource-efficient algorithm. - The message types (
Syn,SynAck, andAck) follow the same pattern as the TCP 3-way handshake message types.
A side note about heartbeats
In most distributed systems, nodes get their presence noticed via heartbeats, and the scuttlebutt algorithm is no different. However, scuttlebutt provides heartbeat implicitly via state reconciliation in two ways:
- Direct heartbeat between node A and B: Node A gossips directly with Node B.
- Indirect heartbeat between node B and C: Node A while gossiping with B shares node C's latest state.
In scuttlebutt algorithm, rather than having a dedicated heartbeat message, every node maintains a heartbeat counter key in its own keyspace that gets updated continuously. This acts as a state change that needs to be propagated naturally like any other value a node wants to advertise or share with others.
How do we distinguish between dead and slow nodes?
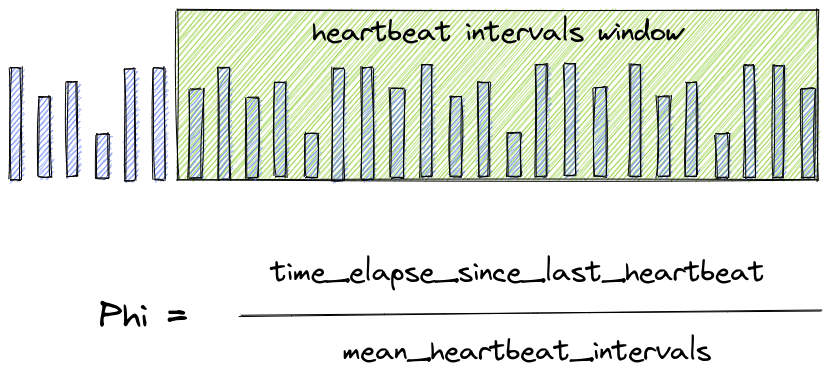
In scuttlebutt, when a node stops sharing updates (stops heart-beating), its state is just left alone. So how can we confidently flag a node as dead or faulty? We could use a timeout but we can do better: using the phi accrual error detection algorithm plays nicely with scuttlebutt. This algorithm calculates the phi value based on a window of recently received heartbeat intervals which is a good approximation that takes into account network delays, packet loss, and app performance fluctuation. By default, we use a window size of 1,000 heartbeat intervals just like Apache Cassandra. The default phi threshold of 8.0 since the paper suggests a value between 8.0 and 12.0. In a real-world scenario, this is really about trading off between quick failure detection and accuracy.
Filling the gap between Chitchat and Quickwit
So far we have explained scuttlebutt and the phi accrual failure detector, which are the core components of our cluster management library implementation (Chitchat). However, some of our requirements in Quickwit still represent challenges for fully integrating with Chitchat.
Some requirements of our practical use case in Quickwit include:
- We want a fresh local state for every run of a node.
- We don’t want obsolete states to keep overwriting new states.
- We want other running nodes to detect that a newly started node’s state prevails all its previous state.
- We want a node to advertise its own public gossip address. Useful for dynamic environments like Kubernetes where some configurations are only known at runtime.
- We want a node id to be the same across subsequent runs for keeping cache data around as long as possible.
As you may have noticed, simple to understand and implement correctly is one of our core guidelines when it comes to solving technical challenges at Quickwit. We refrained from adding more features to Chitchat by observing our needs and choosing the simpler solution along with some tradeoffs. Our solution consists of just leaving Chitchat as-is by defining what a Node Id is and requiring our client (i.e Quickwit) to provide their own customization on top of the Node Id.
Quickwit Node ID implementation
The following describes our Node Id solution:
- Make the id attribute (the node's unique identifier in a cluster) dynamic on every run. That is, we use a different unique id for every run of a node.
- Make the gossip_public_address required when setting up a node. Its value could be extracted from a config item, an environment variable, or computed at runtime.
- Make part of the node id attribute static and related to the physical node to solve the caching requirement.
pub struct NodeId {
id: String, // Unique identifier of this node within a cluster.
gossip_public_address: String, // Node's SocketAddr for peers to use.
}
In Quickwit, this translates into drawing the id from a combination of node_unique_id and node_generation: {node_unique_id}/{node_generation}
node_unique_id: a static unique id or name for the node. Helps in solving the caching requirement.node_generation: a monotonically increasing value. We decided to use the timestamp when the node is starting.
pub struct Member {
node_unique_id: String,
generation: i64,
gossip_public_address: SocketAddr,
}
This solution comes with a few advantages namely:
- No extra measures are needed to avoid the old states from overwriting new states.
- The algorithms (scuttlebutt, phi accrual failure detector) implementations in Chitchat stay close to their respective paper.
- Using timestamp for generation in Quickwit helps keep the nodes stateless.
I hope by now you understand the weird-looking nodeId we saw earlier node-1/1647537681.
Some more issues and tradeoffs to be aware of:
- Keeping node list under control: In Chitchat, every node restart introduces a brand new node. The list of nodes grows within the cluster. Though not critical, this can be undesirable in a highly dynamic environment. We mitigate this by periodically garbage collecting obsolete nodes.
- Timestamp: Using timestamp for node generation still has the potential of reusing a previously used node id due to clock issues. Cassandra solves this by ensuring only nodes within a certain clock range can join the cluster. In our case, since we use a combination of
node_unique_idandnode_generation, there is a very low probability of reusing the same combination. Also, one can completely or partially change the node id when a clock skews in the future and needs to be fixed. - Avoid dead nodes from falsely resurrecting: When a node freshly joins the cluster, its state is populated with all existing node states including dead ones. Since receiving a node state is considered an indirect heartbeat, It can take a few seconds before the newly joined node sorts out dead nodes from live ones. Our solution to this is to avoid gossiping about dead nodes at all. A newly introduced node only cares about live ones moving forward. If a node comes back online, the new node will still notice it anyway. This is as simple as it gets and most importantly paved the way in easily implementing garbage collection on dead nodes.
Wrapping up
In this post, we have explored Chitchat, our new cluster membership management implementation using scuttlebutt gossip reconciliation technique enhanced with the phi accrual failure detector. We first briefly introduced cluster membership, next highlighted the reasons that made us move away from our previous implementation based on SWIM. Then explored the new implementation and described how we have had to tackle some challenges not necessarily addressed in the papers. We believe this lays a great foundation to build on and extend in order to satisfy upcoming feature requirements for Quickwit cluster management functionality. Last but not the least, Chitchat is self-contained enough to be used in other projects.